So let’s crack up this mystery that if there is No SQL in a database then how we can run our queries where there is no SQL, to understand how our queries works in NoSQL database I’m going to introduce to you a method that can make you understand this in very basic level broken down to multiple steps.
Imagine there is a 100 plus floors and each floor there is many offices that communicate between each other or outside and for that to be efficient they need to have a consistence mailing system that would be fast and reliable to deliver their mails in timely manner.
so let’s send 4 people on 4 individual floor to go and collect the Mails, Check, birthday card of even greeting cards individually and list them in a piece of paper that what are the count of each type of mails in each floor as you can see in bellow example.
 Collecting mails example in Hadoop
Collecting mails example in HadoopThen once they go to each individual floor as you see in above visual they go and collect all kinds of mail from each floor and on each floor they group the mails accordingly and write their kinds and count on piece of paper, once that is done they send that through mail delivery to mail deliver boxes to the lobby where they collect and group them like you see in bellow visual.
 Reducer or Grouping in MapReduce or NoSQL query
Reducer or Grouping in MapReduce or NoSQL queryGrouping these 4th floor into 2 floor with the counts and type of mails received from those other 4 floors and making them into two floors is called reducer or grouping which is another term of NoSQL database where you get all kinds of data collect them in their types and make one files out of them.
Once we done with that at the end stage we are going to create another reducer and group those two floor data into one signal worksheet where we run our analyses on them as you can see bellow picture shows a complete diagram of what we have just discussed above that we break them down into multiple parts to understand how it works.
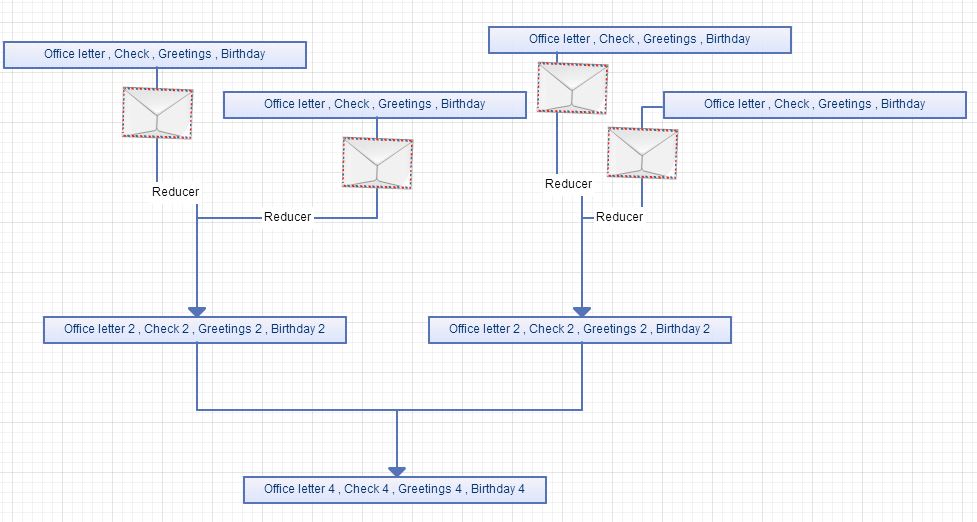 Complete diagram or NoSQL aka MapReducer Query process
Complete diagram or NoSQL aka MapReducer Query processSo there we go we have crack up how running a Query or so called MapReducer works in NoSQL databases that every Hadoop comes with one in nut shell with simple real world example, now days NoSQL query which is MapReduce programming is the heart core of each and every Big Data Database and companies use this to crunch up Big data, now days these process of MapReduce are done automatically with many projects exist in Apache open source world like Hive and pig if you don’t know what Hive is you can read my blog post I have done one in here.
If you have any question or concern you can contact me if you want more details and to get notification when new blog posted you can opt-in to my mailing list and you will never miss any new interesting blog post from me again with great tutorials.

How NoSQL queries work in nut shell.